Using @snoopi_deep results to improve inferrability and control specialization
As indicated in the workflow, the recommended steps to reduce latency are:
- adjust method specialization in your package or its dependencies
- fix problems in type inference
- add precompile directives
The importance of fixing "problems" in type-inference was indicated in the tutorial: successful precompilation requires a chain of ownership, but runtime dispatch (when inference cannot predict the callee) results in breaks in this chain. By improving inferrability, you can convert short, unconnected call-trees into a smaller number of large call-trees that all link back to your package(s).
In practice, it also turns out that opportunities to adjust specialization are often revealed by analyzing inference failures, so we address this topic first.
Throughout this page, we'll use the OptimizeMe demo, which ships with SnoopCompile.
To understand what follows, it's essential to inspect the OptimizeMe source code.
julia> using SnoopCompile
julia> cd(joinpath(pkgdir(SnoopCompile), "examples"))
julia> include("OptimizeMe.jl")
Main.OptimizeMe
julia> tinf = @snoopi_deep OptimizeMe.main()
6-element Vector{Main.OptimizeMe.Object}:
Object x: 1
Object x: 2
Object x: 3
Object x: 4
Object x: 5
Object x: 7
3.14 is great
2.718 is jealous
lotsa containers:
7-element Vector{Main.OptimizeMe.Container}:
Main.OptimizeMe.Container{Int64}(1)
Main.OptimizeMe.Container{UInt8}(0x01)
Main.OptimizeMe.Container{UInt16}(0xffff)
Main.OptimizeMe.Container{Float32}(2.0f0)
Main.OptimizeMe.Container{Char}('a')
Main.OptimizeMe.Container{Vector{Int64}}([0])
Main.OptimizeMe.Container{Tuple{String, Int64}}(("key", 42))
InferenceTimingNode: 1.430486369/2.677729717 on InferenceFrameInfo for Core.Compiler.Timings.ROOT() with 76 direct children
julia> fg = flamegraph(tinf)
Node(FlameGraphs.NodeData(ROOT() at typeinfer.jl:75, 0x00, 0:2677729717))If you visualize fg with ProfileView, you'll see something like this:
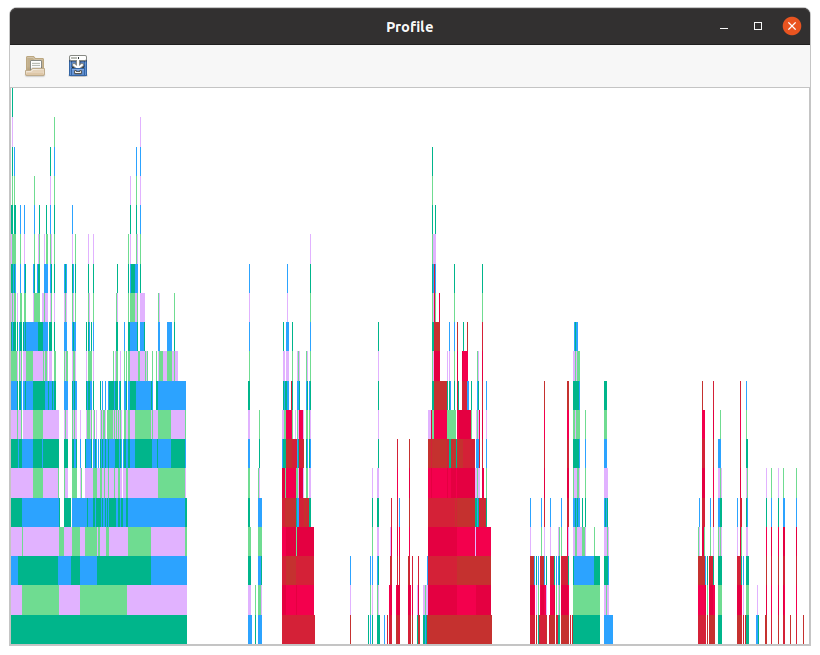
From the standpoint of precompilation, this has some obvious problems:
- even though we called a single method,
OptimizeMe.main(), there are many distinct flames separated by blank spaces. This indicates that many calls are being made by runtime dispatch: each separate flame is a fresh entrance into inference. - several of the flames are marked in red, indicating that they are not precompilable. While SnoopCompile does have the capability to automatically emit
precompiledirectives for the non-red bars that sit on top of the red ones, in some cases the red extends to the highest part of the flame. In such cases there is no available precompile directive, and therefore no way to avoid the cost of type-inference.
Our goal will be to improve the design of OptimizeMe to make it more precompilable.
Analyzing inference triggers
We'll first extract the "triggers" of inference, which is just a repackaging of part of the information contained within tinf. Specifically an InferenceTrigger captures callee/caller relationships that straddle a fresh entrance to type-inference, allowing you to identify which calls were made by runtime dispatch and what MethodInstance they called.
julia> itrigs = inference_triggers(tinf)
75-element Vector{InferenceTrigger}:
Inference triggered to call MethodInstance for combine_eltypes(::Type, ::Tuple{Vector{Any}}) from copy (./broadcast.jl:905) inlined into MethodInstance for contain_list(::Vector{Any}) (/home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:20)
Inference triggered to call MethodInstance for return_type(::Any, ::Any) from combine_eltypes (./broadcast.jl:740) with specialization MethodInstance for combine_eltypes(::Type, ::Tuple{Vector{Any}})
...This indicates that a whopping 75 calls were (1) made by runtime dispatch and (2) the callee had not previously been inferred. (There was a 76th call that had to be inferred, the original call to main(), but by default inference_triggers excludes calls made directly from top-level. You can change that through keyword arguments.) In some cases, this might indicate that you'll need to fix 75 separate callers; fortunately, in many cases fixing the origin of inference problems can fix a number of later callees.
In the REPL, SnoopCompile displays InferenceTriggers with yellow coloration for the callee, red for the caller method, and blue for the caller specialization. This makes it easier to quickly identify the most important information.
Let's start with the first of these and see how it was called:
julia> itrig = itrigs[1]
Inference triggered to call MethodInstance for combine_eltypes(::Type, ::Tuple{Vector{Any}}) from copy (./broadcast.jl:905) inlined into MethodInstance for contain_list(::Vector{Any}) (/home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:20)
julia> stacktrace(itrig.bt)
22-element Vector{Base.StackTraces.StackFrame}:
exit_current_timer at typeinfer.jl:166 [inlined]
typeinf(interp::Core.Compiler.NativeInterpreter, frame::Core.Compiler.InferenceState) at typeinfer.jl:208
typeinf_ext(interp::Core.Compiler.NativeInterpreter, mi::Core.MethodInstance) at typeinfer.jl:835
typeinf_ext_toplevel(interp::Core.Compiler.NativeInterpreter, linfo::Core.MethodInstance) at typeinfer.jl:868
typeinf_ext_toplevel(mi::Core.MethodInstance, world::UInt64) at typeinfer.jl:864
copy at broadcast.jl:905 [inlined]
materialize at broadcast.jl:883 [inlined]
contain_list(list::Vector{Any}) at OptimizeMe.jl:20
main() at OptimizeMe.jl:44
top-level scope at snoopi_deep.jl:53
eval(m::Module, e::Any) at boot.jl:360
eval_user_input(ast::Any, backend::REPL.REPLBackend) at REPL.jl:139
repl_backend_loop(backend::REPL.REPLBackend) at REPL.jl:200
start_repl_backend(backend::REPL.REPLBackend, consumer::Any) at REPL.jl:185
run_repl(repl::REPL.AbstractREPL, consumer::Any; backend_on_current_task::Bool) at REPL.jl:317
run_repl(repl::REPL.AbstractREPL, consumer::Any) at REPL.jl:305
(::Base.var"#872#874"{Bool, Bool, Bool})(REPL::Module) at client.jl:387
#invokelatest#2 at essentials.jl:707 [inlined]
invokelatest at essentials.jl:706 [inlined]
run_main_repl(interactive::Bool, quiet::Bool, banner::Bool, history_file::Bool, color_set::Bool) at client.jl:372
exec_options(opts::Base.JLOptions) at client.jl:302
_start() at client.jl:485Each itrig stores a backtrace captured at the entrance to inference, and that records enough information to identify the caller. You can see that this trigger came from copy at broadcast.jl:905 [inlined], a method in Julia's own broadcasting machinery. edit(itrig) will open the first non-inlined frame in this stacktrace in your editor, which in this case takes you straight to the culprit, contain_list.
Before analyzing this in detail, it's worth noting that main called a very similar function, contain_concrete, before calling contain_list. Why isn't contain_concrete the source of the first inference trigger? The reason is that Julia can successfully infer all the calls in contain_concrete, so there are no calls that required runtime dispatch.
Now, to analyze this trigger in detail, it helps to use ascend:
julia> ascend(itrig)
Choose a call for analysis (q to quit):
combine_eltypes(::Type, ::Tuple{Vector{Any}})
> copy at ./broadcast.jl:905 => materialize at ./broadcast.jl:883 => contain_list(::Vector{Any}) at /home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:20
main() at /home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:44
eval(::Module, ::Any) at ./boot.jl:360
eval_user_input(::Any, ::REPL.REPLBackend) at /home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:139
repl_backend_loop(::REPL.REPLBackend) at /home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:200
start_repl_backend(::REPL.REPLBackend, ::Any) at /home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:185
#run_repl#42(::Bool, ::typeof(REPL.run_repl), ::REPL.AbstractREPL, ::Any) at /home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:317
run_repl(::REPL.AbstractREPL, ::Any) at /home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:305
v (::Base.var"#872#874"{Bool, Bool, Bool})(::Module) at ./client.jl:387
│ ─ %-1 = invoke contain_list(::Vector{Any})::Union{Missing, Regex, String}
Variables
#self#::Core.Const(Main.OptimizeMe.contain_list)
list::Vector{Any}
cs::Union{Vector{_A} where _A, BitVector}
Body::Union{Missing, Regex, String}
@ /home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:20 within `contain_list'
1 ─ %1 = Base.broadcasted(Main.OptimizeMe.Container, list)::Core.PartialStruct(Base.Broadcast.Broadcasted{Base.Broadcast.DefaultArrayStyle{1}, Nothing, Type{Main.OptimizeMe.Container}, Tuple{Vector{Any}}}, Any[Core.Const(Main.OptimizeMe.Container), Tuple{Vector{Any}}, Core.Const(nothing)])
│ (cs = Base.materialize(%1))
│ @ /home/tim/.julia/dev/SnoopCompile/examples/OptimizeMe.jl:21 within `contain_list'
│ %3 = Core._apply_iterate(Base.iterate, Main.OptimizeMe.concat_string, cs)::Union{Missing, Regex, String}
└── return %3
Select a call to descend into or ↩ to ascend. [q]uit. [b]ookmark.
Toggles: [o]ptimize, [w]arn, [v]erbose printing for warntype code, [d]ebuginfo, [s]yntax highlight for Source/LLVM/Native.
Show: [S]ource code, [A]ST, [L]LVM IR, [N]ative code
Actions: [E]dit source code, [R]evise and redisplay
Advanced: dump [P]arams cache.
• %1 = call broadcasted(::Type{Main.OptimizeMe.Container},::Vector{Any})
%2 = call materialize(::Base.Broadcast.Broadcasted{Base.Broadcast.DefaultArrayStyle{1}, Nothing, Type{Main.OptimizeMe.Container}, Tuple{Vector{Any}}})::Union{Vector{_A} where _A, BitVector}
%3 = call concat_string(::Main.OptimizeMe.Container,::Main.OptimizeMe.Container)::Union{Missing, Regex, String}
↩You can learn more about how to use Cthulhu from its documentation and an introductory video. Here we used the down arrow to select the line copy at ./broadcast.jl:905 => materialize at ./broadcast.jl:883 => contain_list(::Vector{Any}), and then hit <Enter> to analyze it in detail. From this, you can immediately tell that the problem starts from the fact that list is a Vector{Any}, and therefore broadcasted(::Type{Main.OptimizeMe.Container},::Vector{Any}) does not know what types to expect it will encounter.
Adding type-assertions
Let's make our first fix. There are several ways we could go about doing this:
- we could delete
contain_listaltogether and usecontain_concretefor everything. - we could create
listas a tuple rather than aVector{Any}; (small) tuples allow inference to succeed even when each element has a different type. This is as simple as changinglist = [2.718, "is jealous"]tolist = (2.718, "is jealous"). - we could use external knowledge to annotate the types of the items in
list::Vector{Any}.
Here we'll illustrate the last of these, since it's the only one that's nontrivial. (It's also often a useful pattern in many real-world contexts, such as cases where you have a Dict{String,Any} but know something about the kinds of value-types associated with particular string keys.) We could rewrite contain_list so it looks like this:
function contain_list(list)
length(list) == 2 || throw(DimensionMismatch("list must have length 2"))
item1 = list[1]::Float64
item2 = list[2]::String
return contain_concrete(item1, item2) # or we could repeat the body of contain_concrete
endThe type-assertions tell inference that the corresponding items have the given types, and assist inference in cases where it has no mechanism to deduce the answer on its own. Julia will throw an error if the type-assertion fails. In some cases, a more forgiving option might be
item1 = convert(Float64, list[1])::Float64which will attempt to convert list[1] to a Float64, and therefore handle a wider range of number types stored in the first element of list. Believe it or not, both the convert() and the ::Float64 type-assertion are necessary: since list[1] is of type Any, Julia will not be able to deduce which convert method will be used to perform the conversion, and it's always possible that someone has written a sloppy convert that doesn't return a value of the requested type. Without that final ::Float64, inference cannot simply assume that the result is a Float64. The type-assert ::Float64 enforces the fact that you're expecting that convert call to actually return a Float64–it will error if it fails to do so, and it's this error that allows inference to be certain that for the purposes of any later code it must be a Float64.
Of course, this just trades one form of inference failure for another–the call to convert will be made by runtime dispatch–but this can nevertheless be a big win for three reasons:
- even though the
convertcall will be made by runtime dispatch, in this particular caseconvert(Float64, ::Float64)is already compiled in Julia itself. Consequently it doesn't require a fresh run of inference. - even in cases where the types are such that
convertmight need to be inferred & compiled, the type-assertion allows Julia to assume thatitem1is henceforth aFloat64. This makes it possible for inference to succeed for any code that follows. When that's a large amount of code, the savings can be considerable.
If we make that fix and start a fresh session, we discover we're down to 70 triggers (a savings of 5 inference triggers).
Declaring container types
Having made the fix above, now the first itrig on the list is
Inference triggered to call MethodInstance for vect(::Int64, ::Vararg{Any, N} where N) from lotsa_containers (/home/tim/.julia/dev/SnoopCompile/examples/OptimizeMeFixed.jl:27) with specialization MethodInstance for lotsa_containers()vect is the call that implements [1, 0x01, 0xffff, 2.0f0, 'a', [0], ("key", 42)] on the corresponding line of lotsa_containers. You can see the first element is an Int, followed by Vararg{Any}. We've used a combination of arguments that evidently hasn't been used before, and creating the vector involves another several inference triggers.
Let's see what kind of object this line creates:
julia> list = [1, 0x01, 0xffff, 2.0f0, 'a', [0], ("key", 42)];
julia> typeof(list)
Vector{Any} (alias for Array{Any, 1})Since it creates a Vector{Any}, perhaps we should just tell Julia to create such an object directly: we modify [1, 0x01, ...] to Any[1, 0x01, ...], so that Julia doesn't have to deduce the container type on its own.
Making this simple 3-character fix gets us down to 64 triggers (a savings of 6 inference triggers).
Reducing specialization
Our next entry takes us back to the broadcasting machinery:
Inference triggered to call MethodInstance for combine_eltypes(::Type, ::Tuple{Vector{Any}}) from copy (./broadcast.jl:905) inlined into MethodInstance for lotsa_containers() (/home/tim/.julia/dev/SnoopCompile/examples/OptimizeMeFixed.jl:28)but this time from lotsa_containers. The culprit,
cs = Container.(list)comes from the fact that we're again broadcasting over a Vector{Any}. This time, however, the type diversity is so high that it's impractical to limit the types via type-asserting: this sure looks like a case where we basically need to be able to handle anything at all.
In such circumstances, sometimes there is nothing you can do. But when the operations that follow are not a major runtime cost (see runtime_inferencetime), one thing you can do is deliberately reduce specialization, and therefore limit the number of times inference needs to run. A detailed examination of itrigs reveals that the next 19 inference triggers are due to this one line, including a set of five like
Inference triggered to call MethodInstance for Main.OptimizeMeFixed.Container(::UInt16) from _broadcast_getindex_evalf (./broadcast.jl:648) inlined into MethodInstance for copyto_nonleaf!(::Vector{Main.OptimizeMeFixed.Container}, ::Base.Broadcast.Broadcasted{Base.Broadcast.DefaultArrayStyle{1}, Tuple{Base.OneTo{Int64}}, Type{Main.OptimizeMeFixed.Container}, Tuple{Base.Broadcast.Extruded{Vector{Any}, Tuple{Bool}, Tuple{Int64}}}}, ::Base.OneTo{Int64}, ::Int64, ::Int64) (./broadcast.jl:1076)
Inference triggered to call MethodInstance for Main.OptimizeMeFixed.Container(::Float32) from _broadcast_getindex_evalf (./broadcast.jl:648) inlined into MethodInstance for copyto_nonleaf!(::Vector{Main.OptimizeMeFixed.Container}, ::Base.Broadcast.Broadcasted{Base.Broadcast.DefaultArrayStyle{1}, Tuple{Base.OneTo{Int64}}, Type{Main.OptimizeMeFixed.Container}, Tuple{Base.Broadcast.Extruded{Vector{Any}, Tuple{Bool}, Tuple{Int64}}}}, ::Base.OneTo{Int64}, ::Int64, ::Int64) (./broadcast.jl:1076)
...corresponding to creating a Container{T} for each specific T for the types in list. In this case, let's imagine that the runtime performance of these objects isn't critical, and so let's decide to create them all as Container{Any}:
cs = Container{Any}.(list)This change gets us all the way down to just 19 remaining triggers (a savings of 45 triggers). Not only did we eliminate the triggers from broadcasting, but we limited the number of different show(::IO, ::Container{T}) MethodInstances we need from later calls in main.
When the Container constructor does more complex operations, in some cases you may find that Container{Any}(args...) still gets specialized for different types of args.... In such cases, you can create a special constructor that instructs Julia to avoid specialization in specific instances, e.g.,
struct Container{T}
field1::T
morefields...
# This constructor permits specialization on `args`
Container{T}(args...) where {T} = new{T}(args...)
# For Container{Any}, we prevent specialization
Container{Any}(@nospecialize(args...)) = new{Any}(args...)
end@nospecialize hints to Julia that it should avoid creating many specializations for different argument types.
Julia's specialization, when used appropriately, can be fantastic for runtime performance, but its cost has to be weighed against the time needed to compile the specializations. Limiting specialization is often the change that yields the greatest latency savings. Sometimes, it can even help runtime performance, if specialization requires that more calls be made via runtime dispatch. Having tools to analyze both runtime and compile-time performance can help you strike the right balance.
Creating "warmpup" methods
Our next case is particularly interesting:
Inference triggered to call MethodInstance for show(::IOContext{Base.TTY}, ::MIME{Symbol("text/plain")}, ::Vector{Main.OptimizeMeFixed.Container{Any}}) from #38 (/home/tim/src/julia-master/usr/share/julia/stdlib/v1.6/REPL/src/REPL.jl:220) with specialization MethodInstance for (::REPL.var"#38#39"{REPL.REPLDisplay{REPL.LineEditREPL}, MIME{Symbol("text/plain")}, Base.RefValue{Any}})(::Any)In this case we see that the method is #38. This is a gensym, or generated symbol, indicating that the method was generated during Julia's lowering pass, and might indicate a macro, a do block or other anonymous function, the generator for a @generated function, etc.
It's particularly worth your while to improve inferrability for gensym-methods. The number assiged to a gensymmed-method may change as you modify the package (possibly due to changes at very difference source-code locations), and so any explicit precompile directives involving gensyms may not have a long useful life.
But not all methods with # in their name are problematic: methods ending in ##kw or that look like ##funcname#39 are keyword and body methods, respectively, for methods that accept keywords. They can be obtained from the main method, and so precompile directives for such methods will not be outdated by incidental changes to the package.
edit(itrig) takes us to
function display(d::REPLDisplay, mime::MIME"text/plain", x)
x = Ref{Any}(x)
with_repl_linfo(d.repl) do io
io = IOContext(io, :limit => true, :module => Main::Module)
get(io, :color, false) && write(io, answer_color(d.repl))
if isdefined(d.repl, :options) && isdefined(d.repl.options, :iocontext)
# this can override the :limit property set initially
io = foldl(IOContext, d.repl.options.iocontext, init=io)
end
show(io, mime, x[])
println(io)
end
return nothing
endThe generated method corresponds to the do block here. The call to show comes from show(io, mime, x[]). This implementation uses a clever trick, wrapping x in a Ref{Any}(x), to prevent specialization of the method defined by the do block on the specific type of x. This trick is designed to limit the number of MethodInstances inferred for this display method.
Unfortunately, from the standpoint of precompilation we have something of a conundrum. It turns out that this trigger corresponds to the first of the big red flames in the flame graph. show(::IOContext{Base.TTY}, ::MIME{Symbol("text/plain")}, ::Vector{Main.OptimizeMe.Container{Any}}) is not precompilable because Base owns the show method for Vector; we might own the element type, but we're leveraging the generic machinery in Base and consequently it owns the method. If these were all packages, you might request its developers to add a precompile directive, but that will work only if the package that owns the method knows about the relevant type. In this situation, Julia's Base module doesn't know about OptimizeMe.Container{Any}, so we're stuck.
There are a couple of ways one might go about improving matters. First, one option is that this should be changed in Julia itself: since the caller, display, has gone to some lengths to reduce specialization, perhaps so too should show(io::IO, ::MIME"text/plain", X::AbstractArray), which is what gets called by that show call in display. Here, we'll pursue a simple "cheat," one that allows us to directly precompile this method. The trick is to link it, via a chain of backedges, to a method that our package owns:
# "Stub" callers for precompilability (we don't use this function for any real work)
function warmup()
mime = MIME("text/plain")
io = Base.stdout::Base.TTY
# Container{Any}
v = [Container{Any}(0)]
show(io, mime, v)
show(IOContext(io), mime, v)
# Object
v = [Object(0)]
show(io, mime, v)
show(IOContext(io), mime, v)
return nothing
end
precompile(warmup, ())We handled not just Vector{Container{Any}} but also Vector{Object}, since that turns out to correspond to the other wide block of red bars. If you make this change, start a fresh session, and recreate the flame graph, you'll see that the wide red flames are gone.
It's worth noting that this warmpup method needed to be carefully written to succeed in its mission. stdout is not inferrable (it's a global that can be replaced by redirect_stdout), so we needed to annotate its type. We also might have been tempted to use a loop, for io in (stdout, IOContext(stdout)) ... end, but inference needs a dedicated call-site where it knows all the types. (Union-splitting can sometimes come to the rescue, but not if the list is long or elements non-inferrable.) The safest option is to make each call from a separate site in the code.
The next trigger, a call to sprint from inside Base.alignment(io::IO, x::Any), could also be handled using this warmup trick, but the flamegraph says this isn't an expensive method to infer. In such cases, it's fine to choose to leave it be.
Defining show methods for custom types
Our next trigger is for show(::IOContext{IOBuffer}, x::Any), a method that has been @nospecialized on x. This is the fallback show method. Most custom types should probably have show methods defined for them, but it's quite easy to forget to add them. Even though the inference time is fairly short, this can be a good reminder that you should get around to writing nice show methods that help your users work with your data types. In this case, Container is so simple there's little advantage in having a dedicated method, so you could just use the fallback and allow this inference trigger to continue to exist. Just to illustrate the concept, though, let's add
Base.show(io::IO, o::Object) = print(io, "Object x: ", o.x)to the module definition.
When you do define a custom show method, you own it, so of course it will be precompilable.
Implementing or requesting precompile directives in upstream packages
Jumping a bit ahead, we get to
Inference triggered to call MethodInstance for show(::IOContext{IOBuffer}, ::Float32) from _show_default (./show.jl:412) with specialization MethodInstance for _show_default(::IOContext{IOBuffer}, ::Any)Looking at the flame graph, this looks like an expensive method to infer. You can check that by listing the children of ROOT in order of inclusive time:
julia> nodes = sort(tinf.children; by=inclusive)
17-element Vector{SnoopCompileCore.InferenceTimingNode}:
InferenceTimingNode: 4.1511e-5/4.1511e-5 on InferenceFrameInfo for ==(::Type, nothing::Nothing) with 0 direct children
InferenceTimingNode: 5.4704e-5/5.4704e-5 on InferenceFrameInfo for Base.typeinfo_eltype(::Type) with 0 direct children
InferenceTimingNode: 8.6196e-5/8.6196e-5 on InferenceFrameInfo for sizeof(::Main.OptimizeMeFixed.Container{Any}) with 0 direct children
InferenceTimingNode: 9.8028e-5/0.0004209 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::Any) with 1 direct children
InferenceTimingNode: 0.00042543/0.00042543 on InferenceFrameInfo for Pair{Symbol, DataType}(::Any, ::Any) with 0 direct children
InferenceTimingNode: 0.000117212/0.0006026919999999999 on InferenceFrameInfo for Base.cat_similar(::UnitRange{Int64}, ::Type, ::Tuple{Int64}) with 1 direct children
InferenceTimingNode: 0.000697067/0.000697067 on InferenceFrameInfo for print(::IOContext{Base.TTY}, ::String, ::String, ::Vararg{String, N} where N) with 0 direct children
InferenceTimingNode: 0.000481464/0.0011528530000000001 on InferenceFrameInfo for Pair(::Symbol, ::Type) with 1 direct children
InferenceTimingNode: 0.000660858/0.0012205710000000002 on InferenceFrameInfo for Base.var"#sprint#386"(::IOContext{Base.TTY}, ::Int64, sprint::typeof(sprint), ::Function, ::Main.OptimizeMeFixed.Object) with 4 direct children
InferenceTimingNode: 0.000727268/0.001424646 on InferenceFrameInfo for Base.var"#sprint#386"(::IOContext{Base.TTY}, ::Int64, sprint::typeof(sprint), ::Function, ::Main.OptimizeMeFixed.Container{Any}) with 4 direct children
InferenceTimingNode: 0.000420439/0.00216088 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::UInt16) with 4 direct children
InferenceTimingNode: 9.0528e-5/0.009614315 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::Tuple{String, Int64}) with 1 direct children
InferenceTimingNode: 0.000560133/0.011189684999999998 on InferenceFrameInfo for (::Base.var"#cat_t##kw")(::NamedTuple{(:dims,), Tuple{Val{1}}}, ::typeof(Base.cat_t), ::Type{Int64}, ::UnitRange{Int64}, ::Vararg{Any, N} where N) with 2 direct children
InferenceTimingNode: 0.000185424/0.011345562999999998 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::Vector{Int64}) with 3 direct children
InferenceTimingNode: 0.002579144/0.016026644 on InferenceFrameInfo for Base.__cat(::Vector{Int64}, ::Tuple{Int64}, ::Tuple{Bool}, ::UnitRange{Int64}, ::Vararg{Any, N} where N) with 12 direct children
InferenceTimingNode: 0.018577433/0.05070554099999999 on InferenceFrameInfo for Base.Ryu.writeshortest(::Vector{UInt8}, ::Int64, ::Float32, ::Bool, ::Bool, ::Bool, ::Int64, ::UInt8, ::Bool, ::UInt8, ::Bool, ::Bool) with 29 direct children
InferenceTimingNode: 0.000114463/0.12183530599999999 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::Float32) with 1 direct childrenYou can see it's the most expensive remaining root, weighing in at around 100ms. This method is defined in the Base.Ryu module,
julia> node = nodes[end]
InferenceTimingNode: 0.000114463/0.12183530599999999 on InferenceFrameInfo for show(::IOContext{IOBuffer}, ::Float32) with 1 direct children
julia> Method(node)
show(io::IO, x::T) where T<:Union{Float16, Float32, Float64} in Base.Ryu at ryu/Ryu.jl:111Now, we could add this to warmup and at least solve the inference problem. However, on the flamegraph you might note that this is followed shortly by a couple of calls to Ryu.writeshortest, followed by a long gap. That hints that other steps, like native code generation, may be expensive. Since these are base Julia methods, and Float32 is a common type, it would make sense to file an issue or pull request that Julia should come shipped with these precompiled–that would cache not only the type-inference but also the native code, and thus represents a far more complete solution.
Later, we'll see how parcel can generate such precompile directives automatically, so this is not a step you need to implement entirely on your own.
Vararg homogenization
Several other triggers come from the show pipeline, but in the interests of avoiding redundancy we'll skip ahead to one last "interesting" case:
julia> itrigscat = itrigs[end-4:end-2]
3-element Vector{InferenceTrigger}:
Inference triggered to call MethodInstance for (::Base.var"#cat_t##kw")(::NamedTuple{(:dims,), Tuple{Val{1}}}, ::typeof(Base.cat_t), ::Type{Int64}, ::UnitRange{Int64}, ::Vararg{Any, N} where N) from _cat (./abstractarray.jl:1630) inlined into MethodInstance for makeobjects() (/home/tim/.julia/dev/SnoopCompile/examples/OptimizeMeFixed.jl:39)
Inference triggered to call MethodInstance for cat_similar(::UnitRange{Int64}, ::Type, ::Tuple{Int64}) from _cat_t (./abstractarray.jl:1636) with specialization MethodInstance for _cat_t(::Val{1}, ::Type{Int64}, ::UnitRange{Int64}, ::Vararg{Any, N} where N)
Inference triggered to call MethodInstance for __cat(::Vector{Int64}, ::Tuple{Int64}, ::Tuple{Bool}, ::UnitRange{Int64}, ::Vararg{Any, N} where N) from _cat_t (./abstractarray.jl:1640) with specialization MethodInstance for _cat_t(::Val{1}, ::Type{Int64}, ::UnitRange{Int64}, ::Vararg{Any, N} where N)A little inspection of the bt fields reveals that all originate from the line
xs = [1:5; 7]and proceed through vcat. Why does this trigger inference? The method of vcat,
julia> @which vcat(1:5, 7)
vcat(X...) in Base at abstractarray.jl:1698is a Varargs method. Julia's heuristics often prevent it from specializing varargs calls, as a means to avoid excessive diversity leading to long compile times. That's a really good thing, but here it would be even better if we could get that method to precompile and avoid running inference altogether. There's an important exception to the heuristics: when all arguments are of the same type, Julia often allows the method to be specialized. Consequently, if we change that line to
xs = [1:5; 7:7]we will get the same output, but all the inputs will be UnitRange{Int} and inference will succeed. This eliminates all three cat-related triggers.
Results from the improvements
An improved version of OptimizeMe can be found in OptimizeMeFixed.jl in the same directory. Let's see where we stand:
julia> tinf = @snoopi_deep OptimizeMeFixed.main()
3.14 is great
2.718 is jealous
...
Object x: 7
InferenceTimingNode: 0.888522055/1.496965222 on InferenceFrameInfo for Core.Compiler.Timings.ROOT() with 15 direct childrenWe've substantially shrunk the overall inclusive time from 2.68s to about 1.5s. Some of this came from our single precompile directive, for warmup. But even more of it came from limiting specialization (using Container{Any} instead of Container) and by making some results easier on type-inference (e.g., our changes for the vcat pipeline).
On the next page, we'll wrap all this up with more explicit precompile directives.